LLM Wiki.
Personal LLM-maintained engineering knowledge vault: Obsidian + Claude Code, with a strict three-layer schema (raw sources, LLM-written wiki, schema spec).
- Year
- 2026
- Role
- Solo Engineer
- Domain
- AI/Tooling

What it does
This project is a personal engineering knowledge vault that is written by an LLM and read by a human. The user drops a source — a PDF, a piece of text, an image, a repository, an audio file — into a raw/ folder, asks Claude Code to ingest it, and Claude writes structured Markdown into the wiki/ folder using a fixed set of templates, with cross-references rendered as Obsidian wikilinks. The deliverable is the vault itself: a disciplined directory tree, a schema specification that lives in the agent’s primary context file, and a small set of CLI workflows that keep the writing layer, the source layer and the search layer cleanly separated. The vault is rendered by Obsidian, not by a custom frontend, so the same Markdown that the agent writes is what the human reads. Source repository is private.
How it’s structured
The vault is organised in three discrete layers that are never allowed to mix. The first layer is raw/, which holds immutable source material — PDFs, text files, images, code repositories — and is read-only to the agent so that ingest cannot corrupt the originals. The second layer is wiki/, which is the only place Claude is allowed to write: it contains the entity-type subfolders, the templates that define each entity’s frontmatter and headings, an index page, and a log that records every ingest and revision. The third layer is the schema itself: CLAUDE.md carries the master schema and the rules every ingest must follow, and wiki/.context.md carries the per-folder schema. Around the three layers, an .mcp.json registers the search server (qmd MCP) that Claude uses to answer queries with citations, and a contracts/ directory holds the frozen stage specs that govern what each release of the vault is allowed to do.
How it works
The vault on disk reflects the three-layer schema directly — wiki/ is partitioned by entity type (concepts, equations, methods, materials, papers, people, phenomena, sources, standards, systems), with raw/ holding the immutable source material and contracts/ carrying the frozen stage specs.
A new ingest goes through a deliberate sequence. The user drops the source into the appropriate raw/ subfolder and runs /ingest <path>. Claude summarises the source, proposes the wiki pages it would create or extend, and waits for explicit approval before writing anything. After approval, Claude writes the new pages under the right entity-type folder using the matching template, updates the index, appends an entry to the log, and surfaces the result for review. The pages themselves use Obsidian’s wikilink syntax — [[Page Name]] — to cross-reference other entities; in reading view those resolve to clickable links, with inline math rendered alongside.
![PID controller entity page rendered in Obsidian-style reading view — wikilinks ([[Integral windup]], [[Ziegler-Nichols tuning]], etc.) shown as resolved purple links to sibling entity pages, with inline math and frontmatter hidden.](/_astro/entity-page-pid-controller.Ct7t_RcP_1X3CXp.webp)
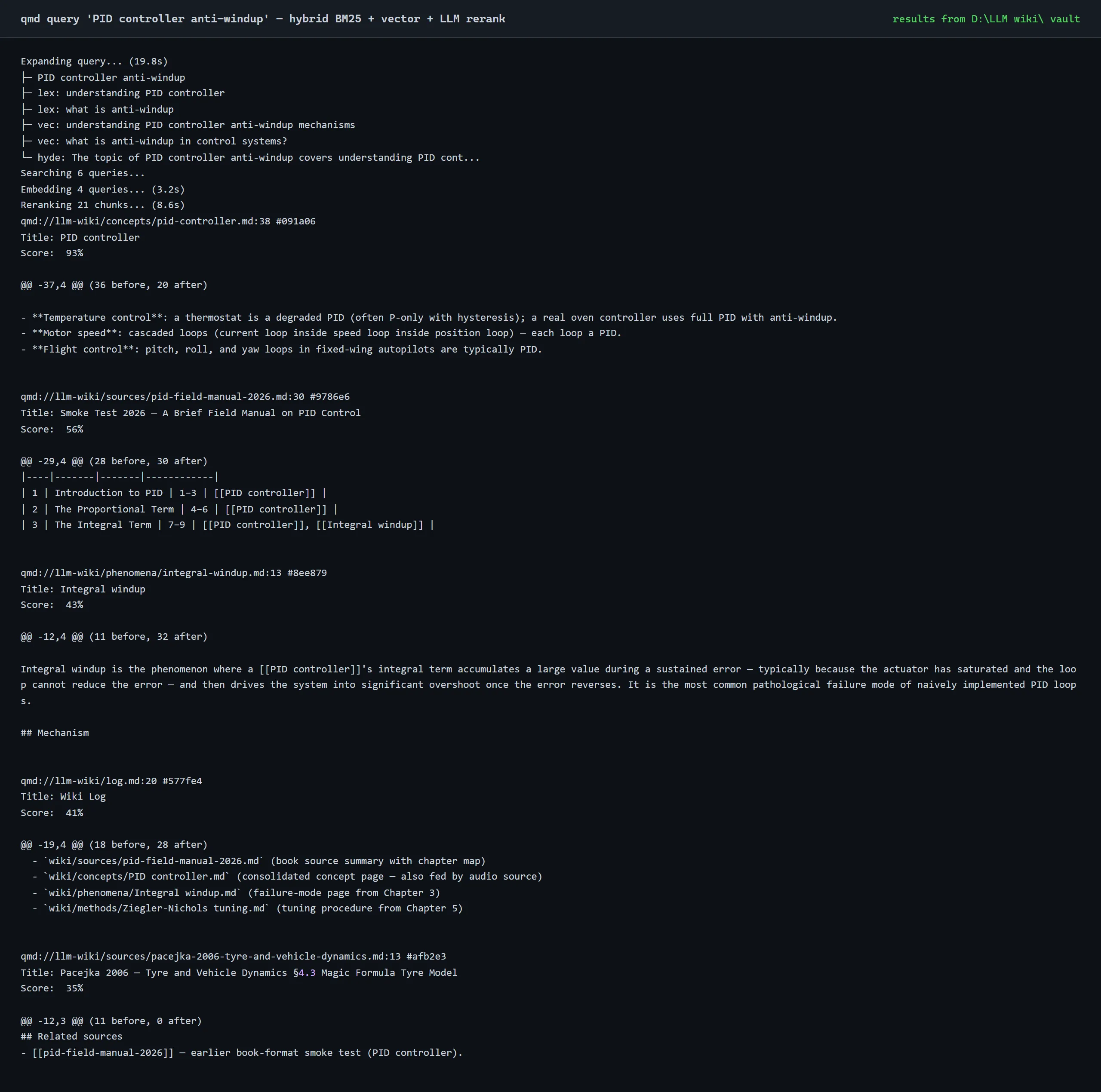
Queries flow the other way: /query "<question>" runs a hybrid search through the qmd MCP server (BM25 keyword + vector + LLM rerank), and Claude answers with [[wikilink]] citations rather than free-form prose, so that every claim points back to a wiki page that points back to a raw source.
Stage 2 of the project added audio ingestion via faster-whisper, with the medium model running CPU-only by default and using CUDA when available; the workflow is the same — source into raw/audio/, transcript and pages written into wiki/.
What I learned
The biggest lesson was that schema enforcement is what makes an LLM-maintained knowledge base actually useful. Templates per entity type, a hard write boundary, an explicit log, and a separate .context.md per folder are the things that keep the vault coherent over hundreds of pages — without them, the LLM produces beautiful prose and unusable structure. I also learned to treat ingest as a two-step ritual: Claude proposes, the human approves, and only then does anything get written. That extra approval step sounds slow but in practice it kept the vault tidy and saved me from re-reading entire passages of a freshly written page just to discover the agent had quietly chosen the wrong template. Finally, wiring a search MCP into the agent so that queries are forced to cite wikilinks turned the vault from a write-heavy archive into something I actually consult — the citations close the loop between writing and reading.